利用样本资料对总体参数进行估计,或在有一定相关关系的随机变量之间,按一定的准则,根据一些随机变量对另一随机变量作最佳估计与预测。
设总体x的分布函数为F(x;θ),其中x1为x的观测值,θ为未知参数,θ的取值范围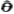 为参数空间。由子样x1,x2,…,xn建立不带有未知参数的统计量f(x1,x2,…,xn)对未知参数θ做出最佳估计,即为参数估计。
为参数空间。由子样x1,x2,…,xn建立不带有未知参数的统计量f(x1,x2,…,xn)对未知参数θ做出最佳估计,即为参数估计。
参数估计分为点估计和区间估计两类。
称f(x1,x2,…,xn)为θ的估计量,记作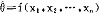 。对于子样观测值(x1,x2,…,xn),称t=f(x1,x2,…,xn)为θ的估计值,建立统计量
。对于子样观测值(x1,x2,…,xn),称t=f(x1,x2,…,xn)为θ的估计值,建立统计量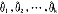 =f(x1,x2,…,xn)作为θ的估计量,即为参数θ的点估计。如果随机变量x的分布函数F(x;θ1,…,θk)中有k个不同的未知参数,则要由子样x1,x2,…,xn建立k个不带有任何未知参数的统计量作为这k个未知参数的估计量,常记作
=f(x1,x2,…,xn)作为θ的估计量,即为参数θ的点估计。如果随机变量x的分布函数F(x;θ1,…,θk)中有k个不同的未知参数,则要由子样x1,x2,…,xn建立k个不带有任何未知参数的统计量作为这k个未知参数的估计量,常记作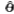 。
。
鉴别估计量好坏的常用标准有:
❶ 无偏性:设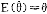 是θ的估计量,当满足
是θ的估计量,当满足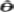 时,称
时,称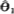 为θ的无偏估计;
为θ的无偏估计;
❷ 有效性:若θ的某估计量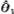 对于除
对于除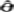 外任何其他的估计量
外任何其他的估计量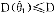 均有
均有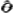 (
(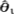 ),则称
),则称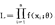 为对θ最有效(具有最小方差)的估计量。
为对θ最有效(具有最小方差)的估计量。
常用的点估计方法有:
❶ 矩估计法:即用子样矩作为总体矩的估计;
❷ 最大似然估计法:由总体分布密度函数f(x;θ),按样本观察值构造似然函数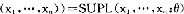 ,选取使
,选取使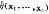 #成立的
#成立的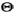
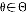 作为θ的估计;
作为θ的估计;
❸ 贝叶斯估计法:依赖于θ的先验分布的估计方法。
还有序贯估计法、最小平方估计法等。
设总体x的分布函数F(x;θ)中的θ为未知参数,由子样x1,…,xn建立两个统计量T1(x1,…,xn)及T2(x1,…,xn),并满足T1<T2,〔T1,T2〕为随机区间。
区间估计的表述为:设α为一给定常数(0<α<1),若P{T1≤θ≤T2}=1-α成立,并用该随机区间作为θ的估计,则〔T1,T2〕是参数θ的置信水平为1-α的区间估计。α为显著性水平,T1、T2分别为上、下置信限。
- 冰茶是什么意思
- 冰草是什么意思
- 冰草叶螨是什么意思
- 冰荡是什么意思
- 冰莹女士小说选是什么意思
- 冰莹抗战文选集是什么意思
- 冰莹近作自选集是什么意思
- 冰菓儿是什么意思
- 冰華是什么意思
- 冰落是什么意思
- 冰著是什么意思
- 冰葫芦是什么意思
- 冰藏是什么意思
- 冰藕是什么意思
- 冰蘖是什么意思
- 冰蘖轩是什么意思
- 冰蘗是什么意思
- 冰蘗之守是什么意思
- 冰蘗之操是什么意思
- 冰虽冷艳,却也追逐“生”的热情是什么意思
- 冰蚀是什么意思
- 冰蚀地貌是什么意思
- 冰蚁是什么意思
- 冰蚕是什么意思
- 冰蚕丝是什么意思
- 冰蚕吐丝是什么意思
- 冰蚕词是什么意思
- 冰蛋加工是什么意思
- 冰蛋品是什么意思
- 冰蛋奶是什么意思
- 冰蛋蛋是什么意思
- 冰蛳散是什么意思
- 冰融是什么意思
- 冰融了是什么意思
- 冰融哒是什么意思
- 冰螺散是什么意思
- 冰蟻是什么意思
- 冰蟾是什么意思
- 冰蟾子是什么意思
- 冰蠶是什么意思
- 冰蠶絲是什么意思
- 冰衔是什么意思
- 冰袋是什么意思
- 冰裂纹是什么意思
- 冰襟雪抱是什么意思
- 冰覆盖度是什么意思
- 冰解是什么意思
- 冰解云散是什么意思
- 冰解冻是什么意思
- 冰解冻释是什么意思
- 冰解壤分是什么意思
- 冰解的破是什么意思
- 冰解雪释是什么意思
- 冰言是什么意思
- 冰誉是什么意思
- 冰谷是什么意思
- 冰赋是什么意思
- 冰趟子战迹地是什么意思
- 冰蹦子是什么意思
- 冰輪是什么意思